
When Greg Storey asked me to help migrate Airbag Industries off Movable Type to a modern publishing setup, I was over the moon — for a few reasons.
For starters, I’ve been an Airbag fan for a long time. I met Greg almost ten years ago while hanging with Dave Shea in Austin for a SXSW, and I’ve enjoyed his wit and insight over the years.
Secondly, Greg told me up front that he wanted to go the static publishing/flat-file route. My only exposure to that kind of setup had been some brief dabbling with Grav a few years back. Since I tend to do a lot of WordPress development for clients, I was excited for a change of pace.
The Platform Selection
Selecting the right platform was our first priority. Greg wanted a flat-file system that got the job done but was only as complex as it needed to be.
I tried out several different platforms and sent Greg my thoughts:
- GatsbyJS: Very heavily focused on React. Introduced a lot of dependencies and felt a bit heavy-handed for a simple publishing site.
- Ghost: I was hopeful for Ghost — I actually funded it in its infancy on Kickstarter. But it’s not a true flat file system. It works similarly to WordPress, with articles living in a database (SQL Lite instead of MySQL) and similar templating and URL routing. The server requirements were also a bit more complex (Node and nginx), so we decided to pass.
- Statamic: Seemed like a decent tool, but my initial impression was that it lacked a bit in polish. The asset management workflow seemed complicated (lots of jumping around to insert assets into a post), and the image manipulation library included (Glide) was a bit complex. We decided that a combination of a solid back-end system like Jekyll/Hugo and a front-end tool like Forestry would simplify a lot of that editorial process.
- Jekyll: I had some experience with Jekyll on a prior project that was using Jekyll for a style guide, so I was leaning toward Jekyll. We actually decided on Jekyll initially, but even with a few hundred posts in our MVP, the build process was slow (~8 seconds). This “lag” was especially noticeable during the template development process when you’d want to test changes to your code.
- Hugo: After our experience with Jekyll and some research about the performance differences between Hugo and Jekyll, we decided to pivot and build the site in Hugo with Forestry at the front end. (Note: Even though we’ve been relatively happy with Forestry, if I had it to do over again, I probably would have gone with Netlify CMS to reduce the complexity of our setup.)
The Hosting Setup
Greg had initially wanted to use a traditional hosting setup where the CMS lives on the server and all the content is stored and edited there. However, that had some limitations, so we considered the pros and cons of two different approaches:
Approach 1: CMS lives on the server, content is stored and edited there
This approach would have simplified the overall infrastructure and could have been powered using something like Statamic or Jekyll’s Admin GUI. Once set up, any changes made to the content would update the flat-files on the server. No deployment needed.
The challenge is that if we wanted to track updates to the site, we’d need to figure out a way to get changes on the server to get committed automatically to Git. Statamic has some custom tools that allow you to set this up to happen automatically, but setting them up seemed a bit complex.
- Pros: Works like Movable Type, publishing happens on the server, no deployment needed
- Cons: Local development is difficult as most development has to happen on the server, extra work to get the content to sync with Git (if versioning is desired).
Approach 2: Site content and code is stored in Git, edited there (or using a service like Forestry or Siteleaf), and pushed to your server changes are made.
We eventually decided a setup like this was most flexible: Hugo (installed a local machine) for rapid site design and development, Forestry (a hosted service) for day-to-day content creation/editing, Github to store it all (endless backups, basically), and Netlify to watch Github for any changes and build/deploy as needed.
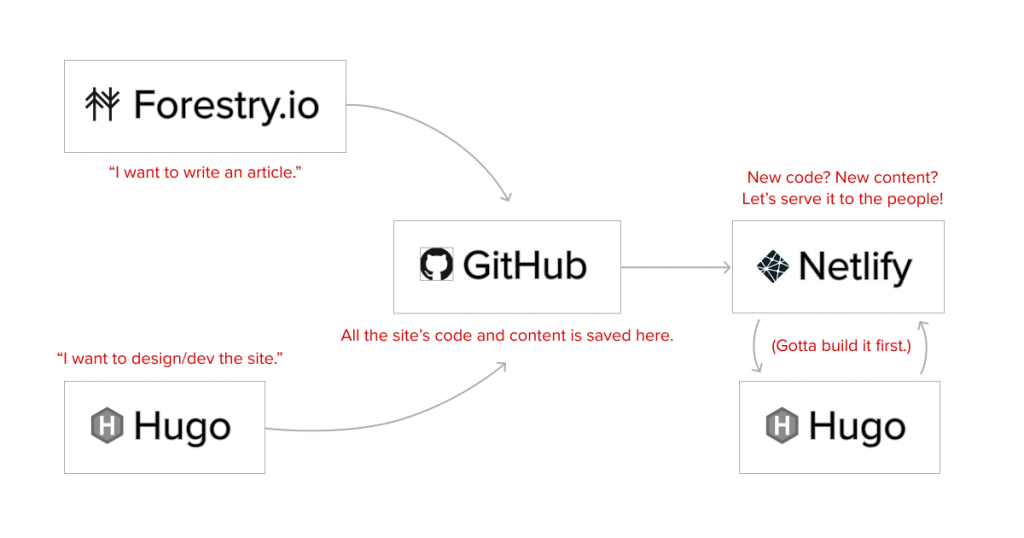
Though it was a little harder to set up and a bit more complicated than the old Movable Type setup, this approach was flexible (you could blog from Github if you wanted to), portable (the site can be quickly checked out on any computer or server), and pretty darn reliable (full site backups on Github and redundancy on every machine where it’s checked out.)
The Project Plan
After we settled on a platform and a host, I sent Greg a high level project plan that looked a little something like this:
- Initial Setup: Set up accounts (Forestry, Netlify, Github) and connect all the things.
- Design / Architecture: Review current design/templates together and discuss what should stay vs. what should change. Talk through the overall IA / UX of the site and create architecture plan for new site (url scheme, nav menu, post types, categories, etc.)
- Migration: Move all assets to the new server, create an export template in Movable Type, and export all the posts to the Jekyll/Hugo flat file format.
- QA/Launch: Set up rewrite rules to make sure people can find old articles, spot check the top articles, switch the DNS, and walk Greg through the new site management process
The Dead Mac ☠️
A few days after I sent Greg a project plan for the migration, I received this email:
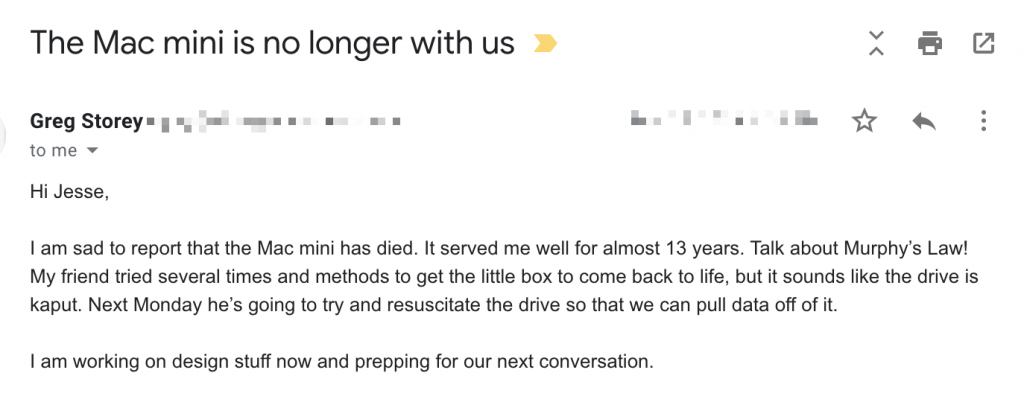
For years, Greg had been running his site with Movable Type on a Mac Mini in his living room, and — just our luck — right as we were ready to begin, the Mac died.
Migrations are almost always messy, a process of connecting two platforms and dealing with incomplete or missing data… so I shouldn’t have been surprised at a bump in the road.
Thankfully, Greg had a JSON export of his content and a zipped backup of the docroot from the year previous, so we weren’t at a complete loss, but my idea of simply exporting the content from MT with a custom template was out the window. I needed to come up with a different approach.
The Migration
I initially toyed with the idea of writing a migration script that would parse the JSON, pull out the relevant data, and write it to a format I needed. But as I begin to look over the JSON, I realized that everything was in there: comments, media, site options. Whatever process had exported this content tried to turn a multi-dimensional database into a flat JSON file, and the results weren’t pretty.
Pivot: OpenRefine
I’m highly pragmatic (read: lazy) when it comes to migrations, so I decided to look for an existing tool to help me deal with this file.
I can’t remember how I found it, but I stumbled upon OpenRefine which declares itself a “free, open source, powerful tool for working with messy data.” That sounded promising.
I installed it and imported the JSON. It’s such an interesting and helpful tool. I read that a lot of libraries use this to clean up large, messy data sets, and I can understand why. It isn’t pretty, and it takes a while to figure out how to use it, but it’s really good for exploring, cleaning, and transforming data however you need.
What I needed was the page title, the slug, the date, and the post content. I was able to pretty quickly drill into the data I needed and export it to a spreadsheet.
Culling Content
Why export the content into a spreadsheet?
Greg had 6000 entries, but a lot of them were links to external sites, many of which were long dead. He wanted to review his content and keep only a fraction of the posts.
To make this easier, I imported the spreadsheet from OpenRefine into Google Sheets and created an extra “keep” column so that Greg could quickly review the list of articles and flag the ones he wanted to keep. We went from 6000 entries to about 600.
Exporting Content
Once Greg had selected the posts he wanted to keep, I put together a script that would export the Google Sheets as individual Markdown files in my Google Drive:
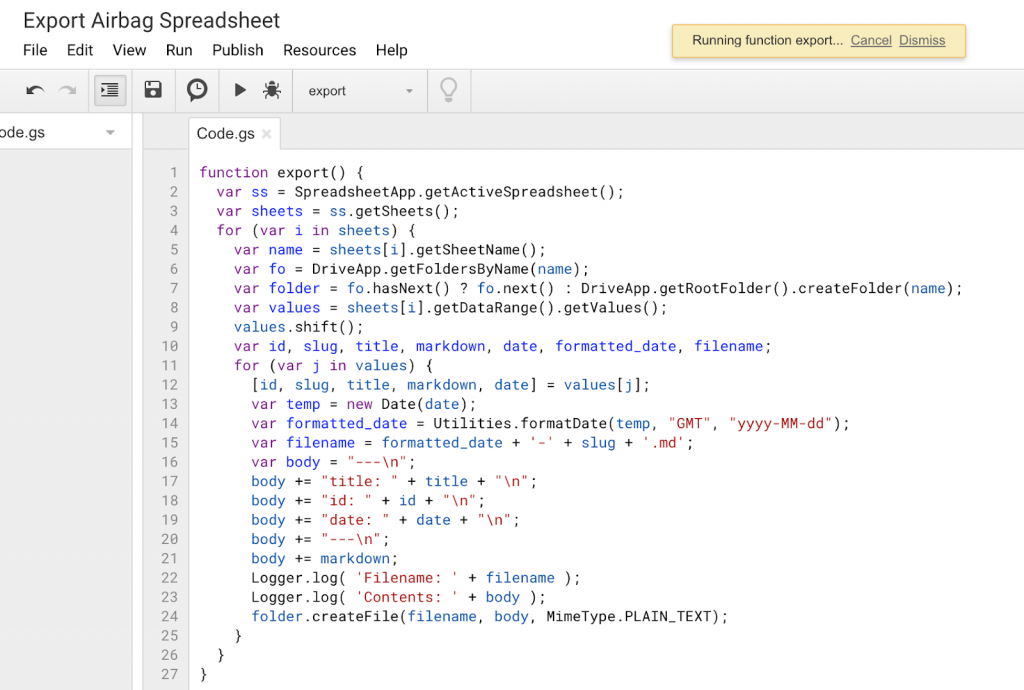
In short, it loops through all the rows in the spreadsheet and creates a file for each in my Google drive with a filename based on the date and slug and the file contents based on the spreadsheet contents.
Basically, this script outputs the flat Markdown files our static site generator needs. I was able to drop these files into the content/posts folder and Hugo processed them with no trouble.
Cleaning Up Content
We weren’t done, though. Even though the content had been exported, there were significant character encoding issues.
Line Breaks
At first, I thought I had botched the export of content from the JSON file, collapsing the extra line breaks that tell Markdown to render <p> instead of <br> but after reviewing the JSON files, I realized that both the markup and HTML output in the JSON file didn’t have these breaks. The HTML included only <br> tags and the Markdown only had a single newline.
The good news is that thanks to a good old fashioned Linux one-liner (sed -i.bak G *), I was able to add a new line to every line break for every post, which resolved the issue. This posed a problem for lists, which require hyphens at the beginning of the line and no break between, but I was able to clean that up. I know that’s probably TMI… but the end result was that posts correctly rendered paragraph blocks instead of just line breaks.
Character encoding
The source content contained a lot character encoding issues, specifically mixed encoding issues (e.g. a character has been encoded twice), even in the source file. This was especially annoying, and I thought I was going to have to use something industrial strength like this killer Python library called FTFY that seems to handle this botched encoding pretty well .
However, since we had moved everything into flat files, I found that it was much faster to do some smart search/replace magic to address character encoding issues with em dash, en dash, ellipses, and curly single and double quotes. All in all, about 160 articles were updated.
Block quotes
Because Greg tends to quote external articles, I also ran a few regular expressions to transform a quote class for block quotes into Markdown’s block quote syntax.

Asset references
Thankfully, we didn’t have too many asset references in the content that we had to deal with. I copied whatever assets were included in the posts (generally referenced in bucket and images folders) to a new uploads folder. That way, I could set up a redirect so any requests for /bucket/ or /images/ get passed to /uploads/. Incidentally, Forestry uploads media assets to the /uploads/ folder, so this strategy worked out well.
Templating
It was a bit of a learning curve for me to figure out Hugo. The directory structure, content organization, and templating (Hugo uses the “Go” templating language) were all foreign to me, but the Hugo documentation is solid. Also, The Airbag Industries site has a relatively straightforward content model — posts, pages, a menu, an archive page, and a site feed — so building out the site was relatively simple.
One other note about building with Hugo: I love how simple the setup was. I avoided the boilerplates because I didn’t want the additional complexity of including Gulp or any kind of Node modules. We weren’t compiling JS, and Hugo Pipes lets you process SASS files without a complex dependency chain. I can’t tell you how excited I am that I only need to check out a repo, install Hugo and run hugo serve when developing for the site.
I also can’t say enough how helpful Sara Soueidan’s article on moving from Jekyll to Hugo was throughout this process. It helped me tremendously. If you’re building a site on Hugo, do yourself a favor and read the whole thing. Lots of practical information in there.
Rewrite Rules
The last key step for the project was setting up URL rewrite rules so that old links still worked.
I thought I’d be able to grab the slug from the JSON export and use it to handle the redirects, e.g. /archives/airbag/{SLUG}.php → /{SLUG}/. However, I discovered late in the process that the slug in the JSON export and the actual page locations on site didn’t match. Darn. (See earlier point about migrations being messy.)
It turns out that his Movable Type setup had some custom rules for slugs: capped at 15 characters, using _ instead of - for spaces, and eliminating hyphens. It also seems like some slugs have been automatically truncated (e.g. Latte Induced Thinking →latte_induced_t.php) while others have been manually truncated (e.g. Attack Pattern Delta → attack_pattern.php).
We decide to put the aforementioned redirect in place (Netlify lets you define redirects in a netlify.toml file at the root of your site):
# Redirect for legacy permalinks
[[redirects]]
from = “/archives/airbag/*.php”
to = “/:splat”
This handled a good percentage of the articles and most titles were under 15 characters. For articles that didn’t match the pattern, we just put in manual redirects.
Site Launch 🍾
I’d like to thank @plasticmind and @ATXDodger for their contributions to the redesign and development of an old website that was due for a refresh. It’s still a bit of a work in progress but I am thrilled to see Airbag 3.0 go live. More to come!https://t.co/PbxSIICEJ9
— Greg Storey (@Brilliantcrank) March 3, 2020
We successfully launched the site a few months ago, and more recently Greg worked with Stephen Caver to freshen up the design. Thanks for Greg for the opportunity to be a part of this project!
Post-mortem
This project took a bit longer than expected, and it wasn’t just because of the unexpected dead Mac. Some of the things that made this take a bit longer:
- **My general unfamiliarity with flat-file systems.** This unfamiliarity meant a fair bit of learning up front. The biggest challenge was trying to figure out the nuances around template inheritance and content loops (both are common concepts in WordPress, but they were different enough to hang me up a bit.)
- **Switching platforms mid-build.** Only once I got the bulk of the articles pulled into Jekyll did the slow build time really become a problem. Thankfully, Hugo’s setup and templating aren’t too dissimilar from Jekyll, and nearly all of the content’s formatting stayed the same, so the switch wasn’t as painful as it could have been.
- **Switching hosts mid-build.** I tried for a while to get Hugo publishing to a more traditional host, but it required *one more tool* to manage deployments (Deploybot) and because deployment and hosting weren’t integrated, every deployment took a while, making the entire setup feel especially slow. Switching to Netlify for integrated hosting and deployment sped this whole process up.
- **No database.** While I knew this was a problem early on, it did add 30-40% more effort to the project overall. Even though we had a JSON dump of the content, it was filled with lots of malformed or double-encoded characters which required significant amounts of TLC.